Follow along with these worked examples to gain an idea of how the Column Merge App can help you combine data from across the processor's outputs.
Example 1: Find all the IIIF manifest URIs for manuscripts containing musical notation.
Suppose you are interested in performing a digital analysis of a large corpus of musical manuscripts, and you therefore need to find those manuscripts with IIIF manifest URIs which also contain musical notation. This is not immediately possible with the default output data, since the IIIF manifest URIs are contained in 01_records, while the details of musical notation are predominantly included in 06_music. To combine the two sets of information, we can follow the steps below:
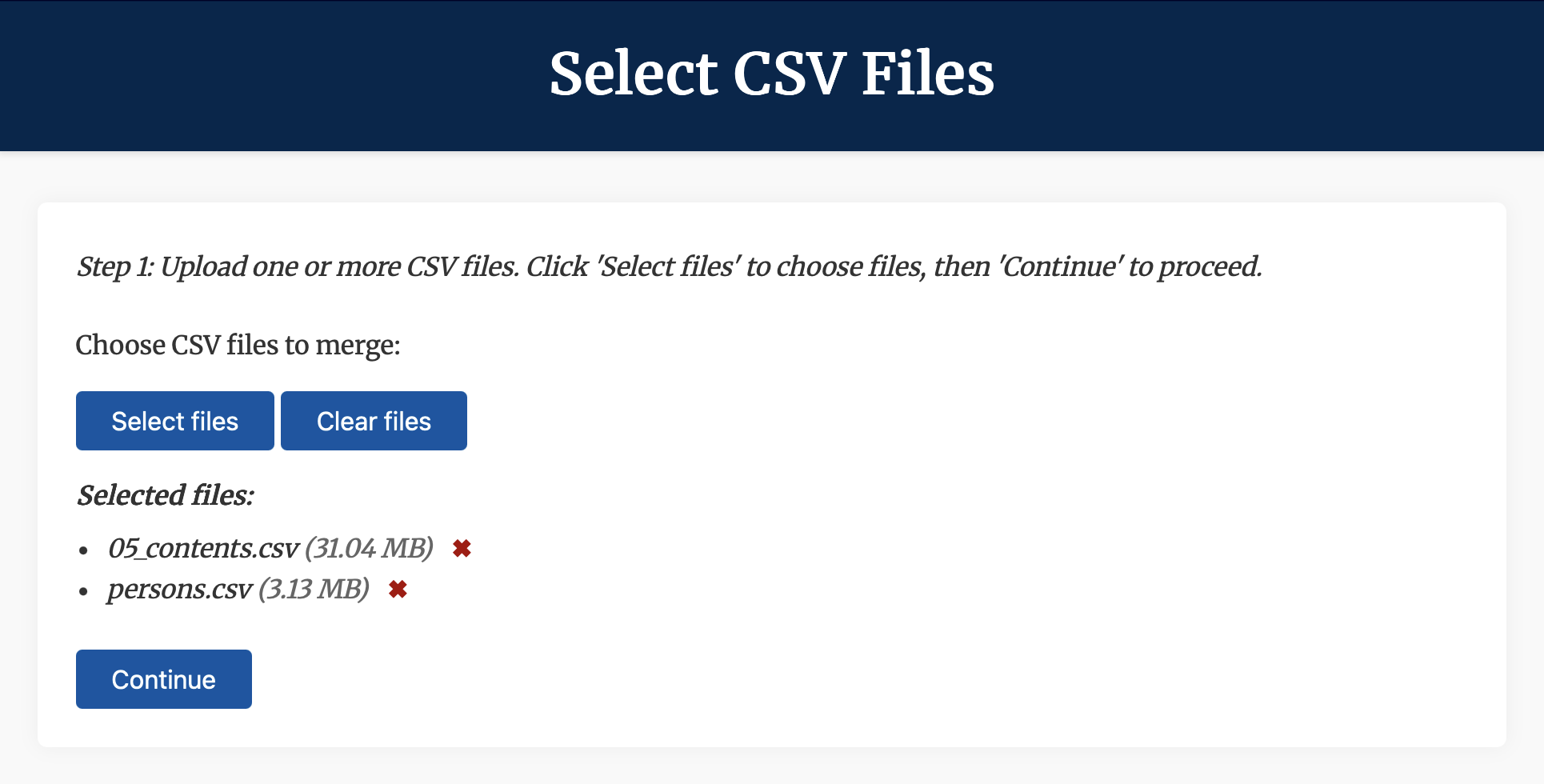
- With the Column Merge app running (see the steps in the preceding section), navigate to http://127.0.0.1:5000/ in your web browser.
- Click/tap on
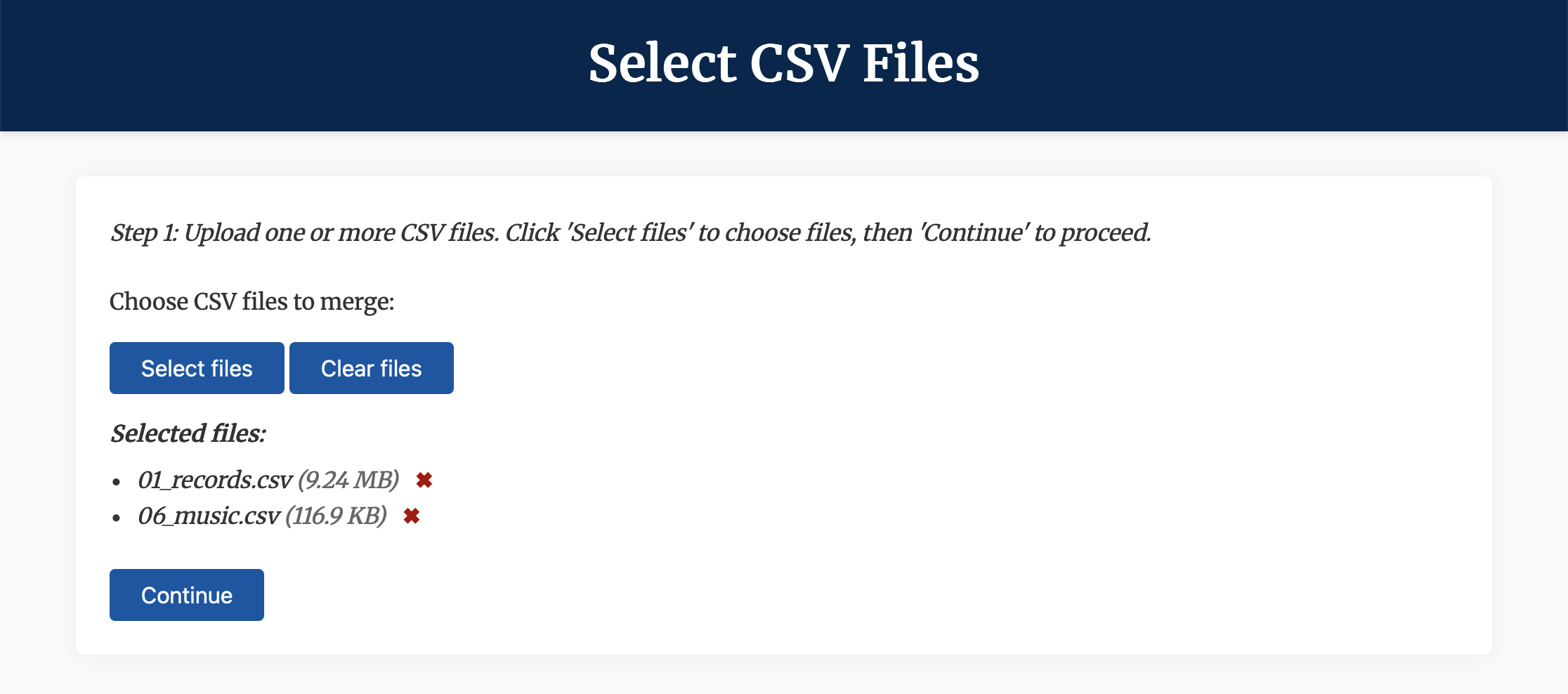
Select filesand navigate to thetabular_data/output/collection/csvdirectory, where the CSV output files for the collection are stored. - Select
01_records.csvand06_music.csv, the two files we want to merge. - Click/tap
Continue, and wait for the files to process. - On the next page (
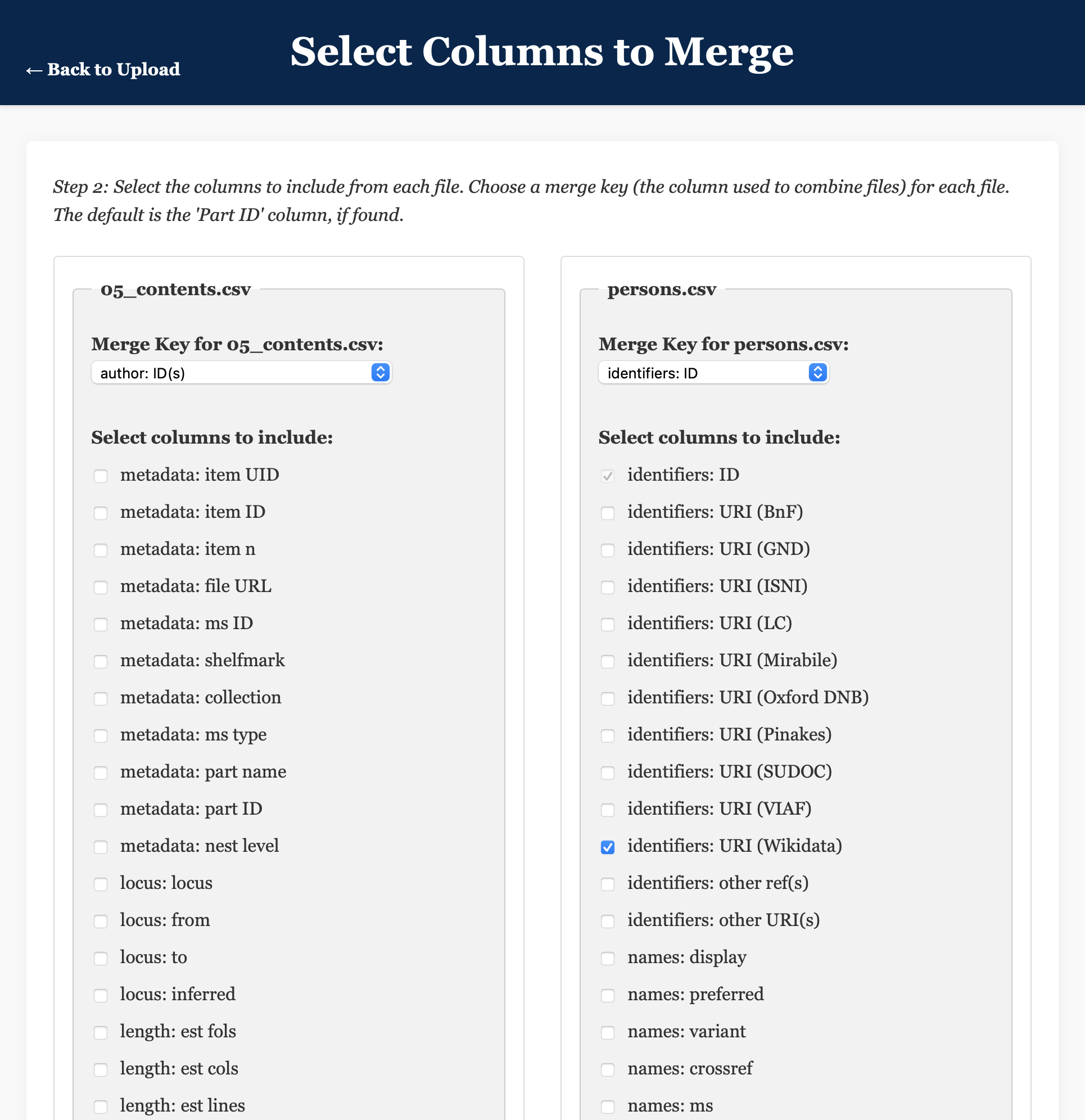
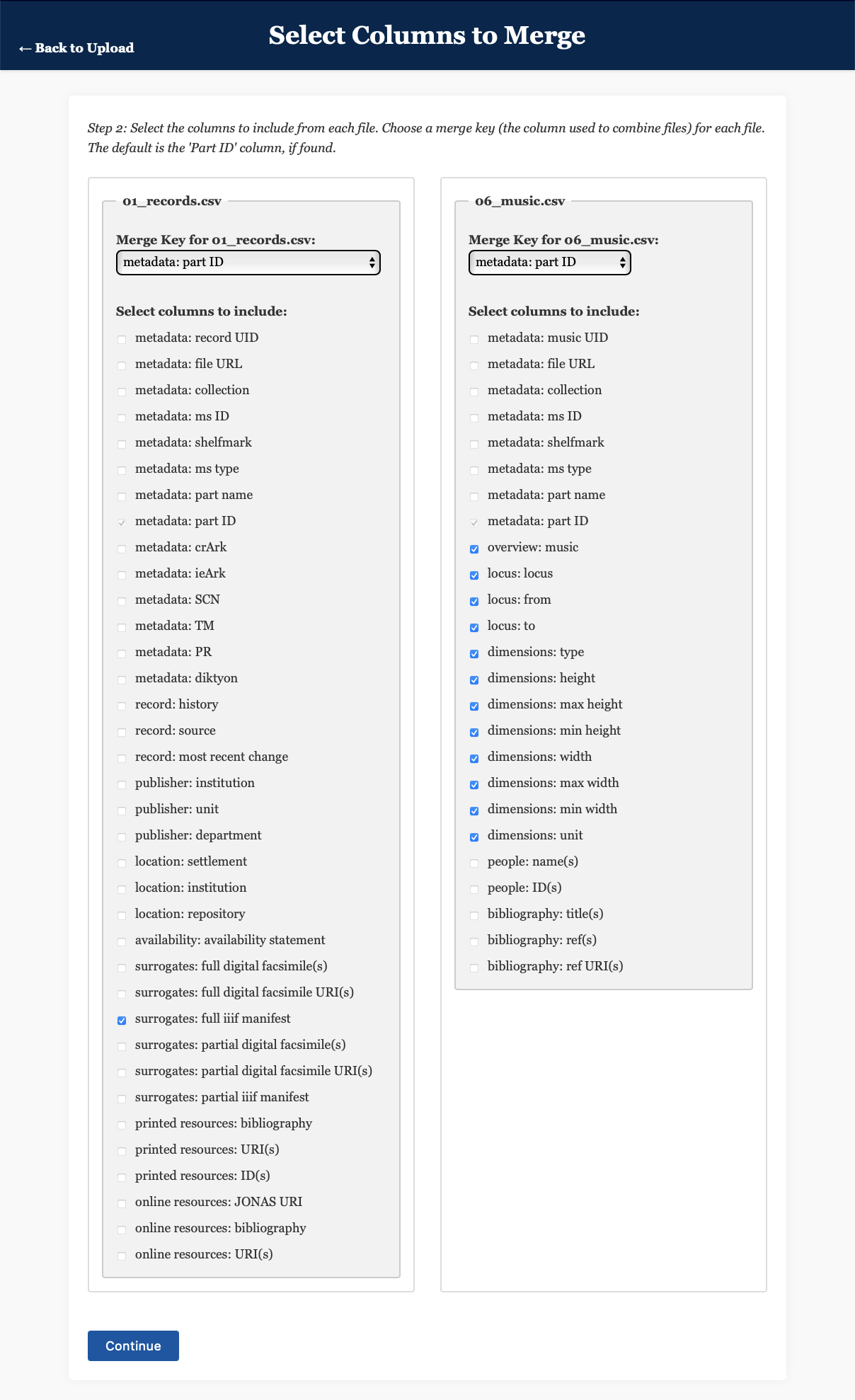
Select Columns to Merge), we need to select the columns that we want to retain from each CSV file. TheMerge Key(the column used to combine the files) can stay asmetadata: part ID, since this will correctly align the files based on their shared identifiers. In the left-hand column (01_records.csv), tick the box labelledsurrogates: full iiif manifestto tell the app that you want to retain this column. - In the right-hand column, select the columns from
overview: musicthrough todimensions: unit, to retain information that might be useful for a digital study of musical notation. - Click/tap
Continue. - On the next page (
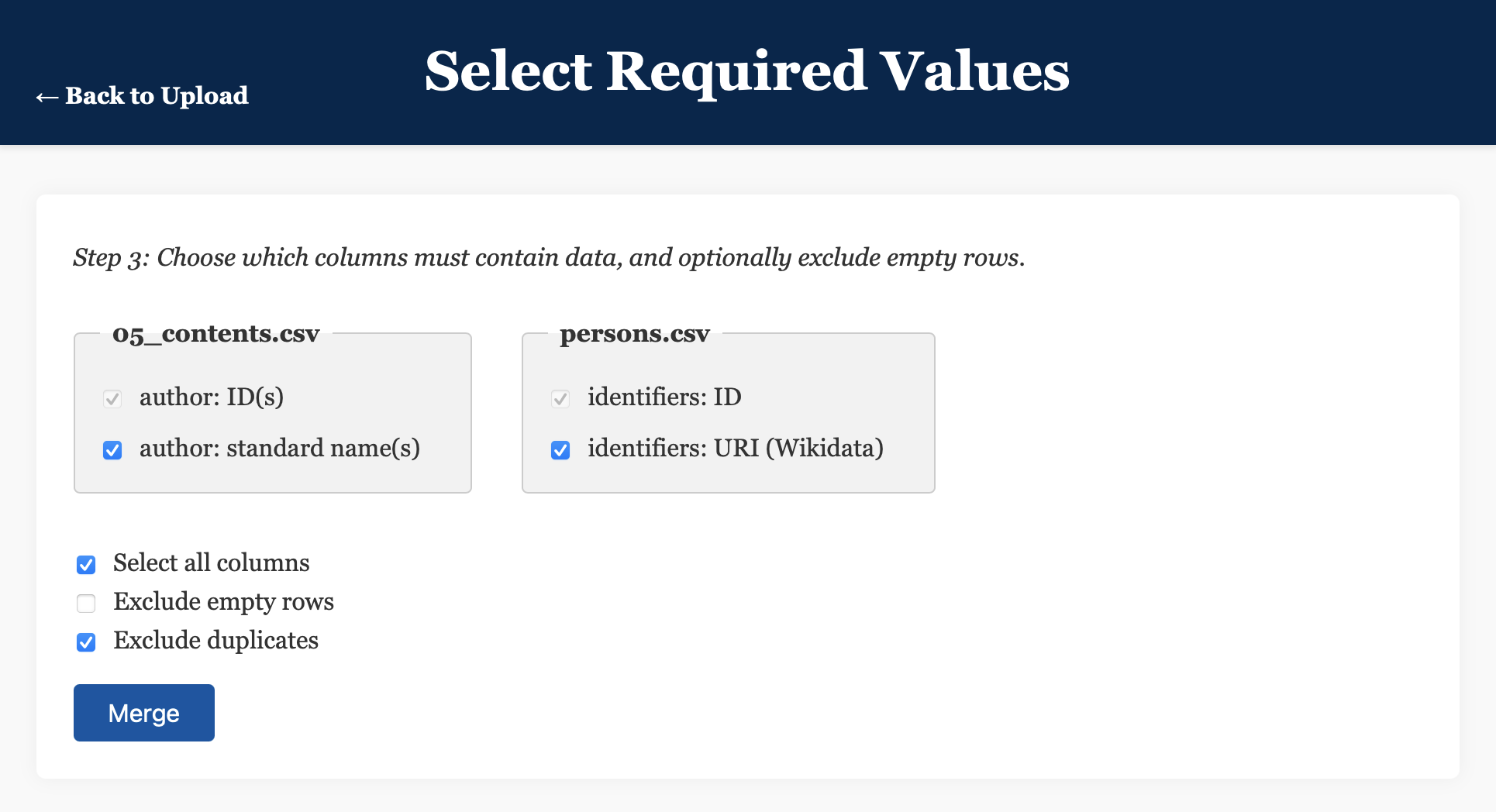
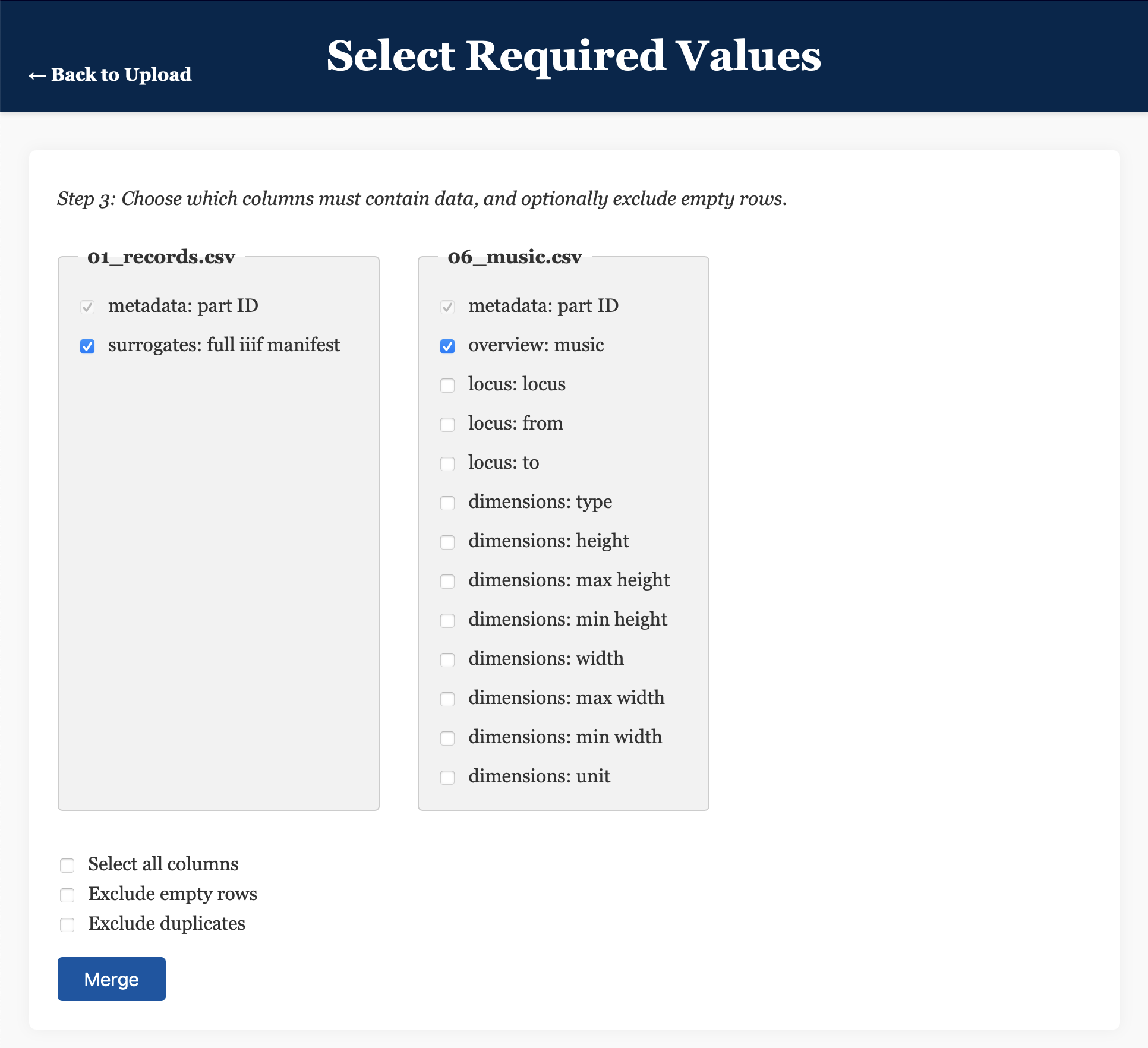
Select Required Values), we need to select the columns for which data must appear in a given row in order for that row to be included. Given that we’re only interested in manuscripts with a IIIF manifest file, ticksurrogates: full iiif manifestin the left-hand column. - Also select
overview: musicin the right-hand column, to select only those manuscripts for which details of musical notation have been included in the catalogue. - Click/tap
Merge. - On the next page (
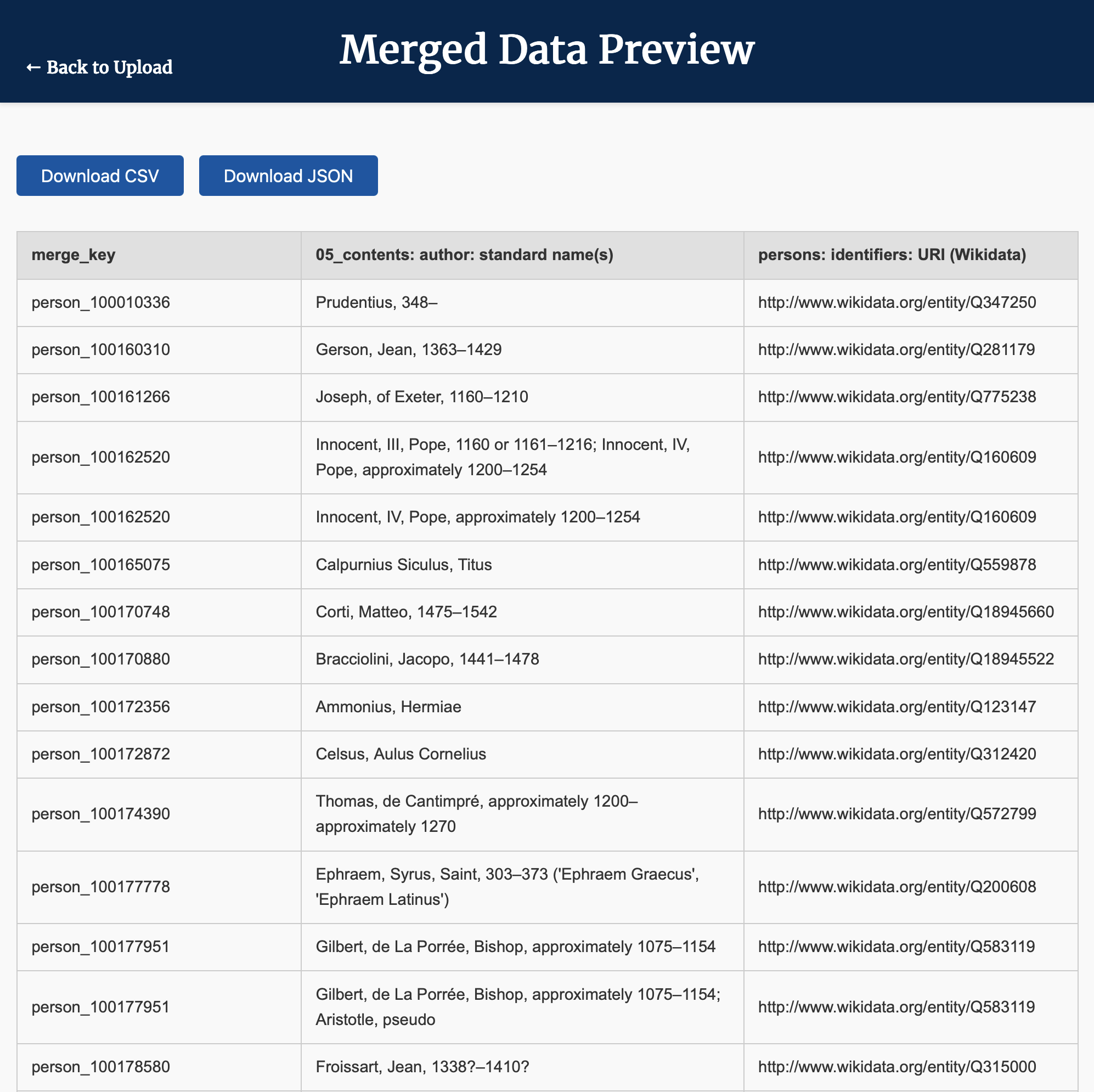
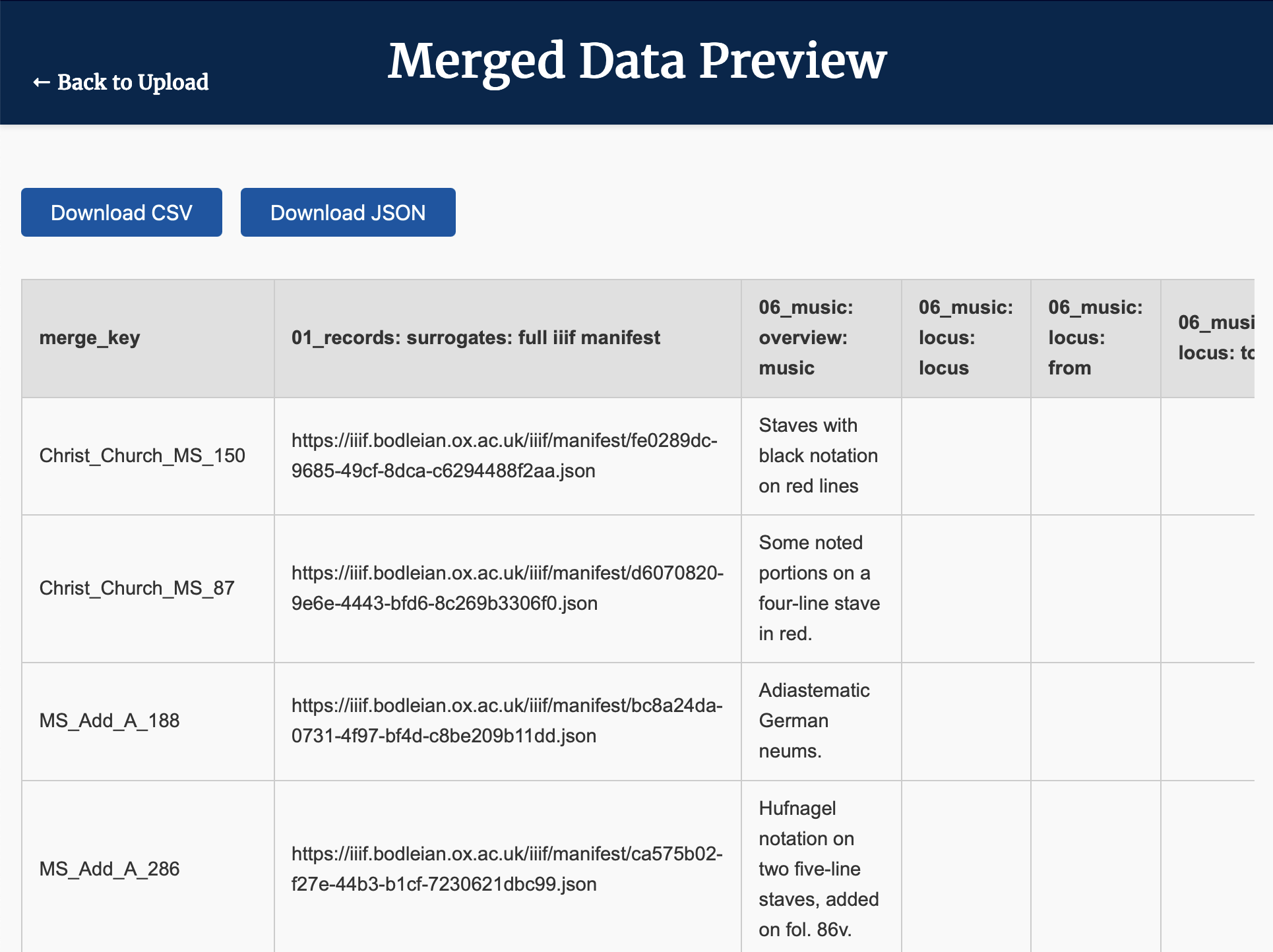
Merged Data Preview), you will see a preview of the merged table, with the merge key (in this case, the manuscript part ID) in the first column, followed by the IIIF manifests and then details of the musical notation. - To download the data in either CSV or JSON format, click/tap on the appropriate button at the top of the page.
Example 2: Find available WikiData references for people referenced as authors.
Suppose now that you are interested in connecting the data found in the MMOL catalogue about authors to other sources of linked open data, such as Wikidata, and therefore want to know their Wikidata references. This is not immediately possible with the default output data, since details of authors are predominantly included in 05_contents, while Wikidata references are stored in the persons section of the authority output. To combine the two sets of information, we can follow the steps below:
- With the Column Merge app running (see the steps above), navigate to http://127.0.0.1:5000/ in your web browser.
- Click/tap on
Select filesand navigate to thetabular_data/output/collection/csvdirectory, where the CSV output files for the collection are stored. - Select
05_contents.csv, the first of the two files that we want to merge. - Click/tap on
Select filesagain, and navigate to thetabular_data/output/authority/csvdirectory, where the CSV output files for the authority data are stored. - Select
persons.csv, the second of the two files that we want to merge. - Click/tap
Continue, and wait for the files to process.05_contents.csvis a large file, so this may take some time. - On the next page (
Select Columns to Merge), we need to select the columns that we want to retain from each CSV file. We want to combine the tables based on the identifiers associated with the authors, so change theMerge Keyvalue for05_contents.csvtoauthor: ID(s), and change the value forpersons.csvtoidentifiers: ID. - In the left-hand column, select
author: standard name(s), to include the author’s name. - In the right-hand column, select
identifiers: URI (Wikidata)which is the Wikidata reference we want to associate with each author. - Click/tap
Continue. - On the next page (
Select Required Values), we need to select the columns for which data must appear in a given row in order for that row to be included. This time, we can tickSelect all columnsandExclude duplicates, since we only want entries containing all three values, and there is no value in this case of retaining duplicate rows. - Click/tap
Merge. - On the next page (
Merged Data Preview), you will see a preview of the merged table, with the merge key (in this case, the person identifier) in the first column, followed by the text associated with a given author, their name, and their Wikidata reference. - To download the data in either CSV or JSON format, click/tap on the appropriate button at the top of the page.